摘要
数据的存储方式对应用程序的整体性能有着极大的影响。对数据的存取,是顺利读写还是随机读写?将数据放磁盘上还将数据放flash卡上?多线程读写对性能影响?面对着多种数据存储方式,我们如何选择?本文给大家提供了一份不同存储模式下的性能测试数据,方便大家在今后的程序开发过程中可以利用这份数据选择合适的数据存储模式。
TAG
存储性能,innodb性能,存储介质
目录
目录… 1
简介… 1
存储性能分析… 2
测试程序说明:… 2
存储测试数据:… 2
Mysql innodb性能测试… 4
Mysql(InnoDB)刷盘策略… 6
c/s模式通信性能… 6
直接文件存储… 7
文件IO方式… 7
完全随机写还是跳跃,5倍的性能差距… 8
多线程随机读、处理速度、响应时间… 9
系统缓存… 10
系统缓存相关的几个内核参数… 10
dirty页的write back. 10
总结… 11
简介
数据的存储方式对应用程序的整体性能有着极大的影响。对数据的存取,是顺利读写还是随机读写?将数据放磁盘上还将数据放flash卡上?多线程读写对性能影响?面对着多种数据存储方式,我们如何选择?
本文会对不同存储方式做详细的性能测试,以提供给大家一份不同存储方式下的性能测试数据为主,同时会简单介绍各种存储方式之间的性能差异。
存储性能分析
影响储存速度有各个方面的原因,包括存储介质、读写盘方式以及硬件环境对读写盘时的影响。这里主要分享存储速度的一些调研结果。
硬件环境如下:
CPU: INTER Nehalem E5620 2.4GHZx2
内存: PC-8500 4GB*8
硬盘: 300G 10k*2, RAID:1
Flash: SSD 160GB_MLC X25-M G2×6
网卡: 千兆
数据量:117G
测试程序说明:
测试共分两套程序:
- A. 存储测试
a) 存储测试程序均使用pread/pwrite进行存储测试,块链遍历速度采用frs开发的块链库进行。
b) 为了减少随机读写时系统缓存带来的影响
i. 将数据量增大至117G
ii. 每次数据只被测试一次
iii.程序入口处清内存
c) 测顺序读写时,一次读写所有数据。
d) 测随机读写时,每次读4KB,读381MB。
- B. 网络性能测试
a) 采用ub + ubrpc实现压力工具的服务器端和客户端。
b) UBSVR_NODELAY
c) 常用的Idl规范
d) 对两个不同大小的包请求进行测试
存储测试数据:
磁盘
顺序读:145.59MB/s
随机读:0.91MB/s (每次读4KB,读381MB)
顺序写:83.1MB/s
随机写:0.34MB/s (每次写4KB, 写381MB)
Flash
顺序读:61.5MB/s
随机读:14.9MB/s (每次读4KB,读381MB)
顺序写:59.8MB/s
随机写:1.93MB/s (每次写4KB, 写381MB)
内存
顺序写:1655MB/s
随机写:1496MB/s
Eg: 块链遍历速度1000万元素, 565582 us
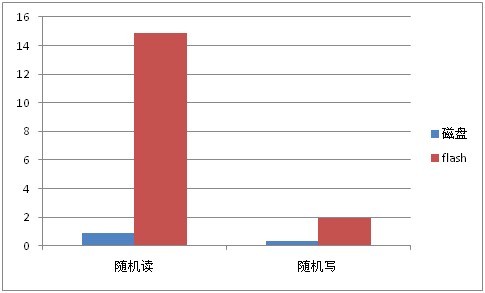
磁盘与flash卡的顺序读写性能对比(单位MB):
磁盘与flash卡的随机读写性能对比(单位MB):
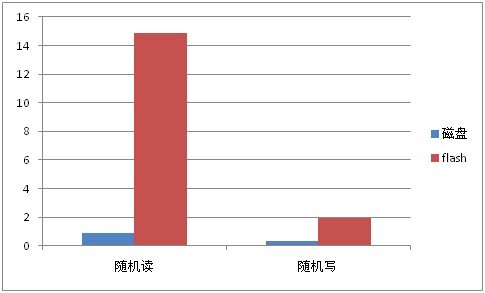
对比磁盘和flash卡的随机读写性能,我们可以看到:对于写操作而言,其在磁盘和flash卡上的性能差异较小,且事实上其性能差异会随着随机写时每次写入的数据量以及flash卡块大小等其它因素而产生波动;同时,在带写优化的flash上,当将数据写入flash卡时,数据会先写到一块buffer中,当满足一定条件(如buffer满)后,会将buffer的数据刷入flash,此时会阻塞写,因此会带来性能抖动。所以,当应用程序的多数操作是写入操作时,若没有flash卡也可以勉强将数据放到磁盘上。
但是相反,从测试结果看,在磁盘和flash卡上的随机读性能有着8倍甚至更多的差距,所以当程序读磁盘操作相当多时,把数据放到flash卡上是一个比较好的选择。比如,对于一个随机查询较多数据库应用程序,我们可以考虑把数据库的存储文件放到flash卡上。
另一方面,我们可以直观地看到,无论顺序读还是顺序写,在磁盘上的速度都远远高于在flash卡上的速度。所以如果程序所需的数据是从磁盘一次载入,载入后对数据的修改都是内存操作,不直接写盘,当需要写盘时,也是一次将内存中的数据dump到磁盘上时。我们都应该将数据放到磁盘,而不是flash卡上。
Mysql innodb性能测试
Mysql测试一:存读
硬盘环境与配置:
innodb_buffer_pool_size = 5120M
innodb_flush_log_at_trx_commit = 0
机器内存:32G
cpu:4核 Intel(R) Xeon(R) CPU 5150 @ 2.66GHz
flash:256G,slc 没有写优化,没有raid。
压力:
mysqlab args:-uroot -proot -h127.0.0.1 -P3306 -dfrs -fr.sql -c1 –t40 -s1000
50个线程,每个线程1000req/s的压力:
结论:
| 每秒处理次数 |
4700左右。 |
| max响应时间 |
139374 us |
| 平均响应时间 |
8535us |
|
|
iostat:
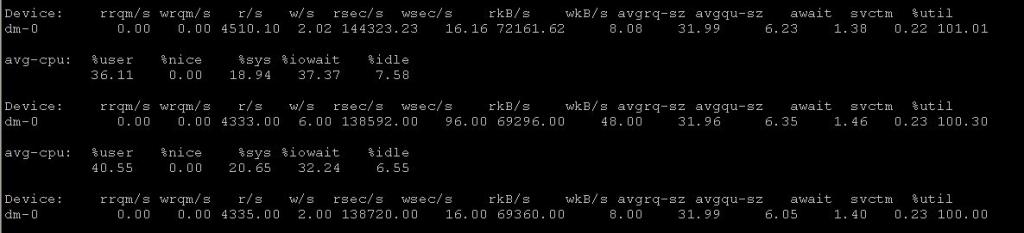
从系统状态来看,
flash性能已经到极限。
Mysql测试二:读写冲突测试
| 读压力 |
真实压力 |
写压力 |
真实写压力 |
| 0 |
0 |
单线程1000 |
300左右(起初很快,但最终会降下来) |
| 0 |
0 |
10线程*1000 |
300左右(起初很快,但会降下来,降下来后,很不稳定) |
| 40线程*80 |
2000上下浮动 |
单线程300 |
平均60+ |
| 40线程*50 |
1000+上下浮动 |
单线程300 |
平均80+ |
| 40线程*40 |
1500 |
单线程100 |
80+ |
可见,flash读写冲突非常严重,如果压力太高,会导致被压垮,反而在写压力恒定在100次的时候,可以支持1500以上的并发读请求,且比较稳定。
线上,最还还是使用写优化的mlc。以减少读写冲突。
Mysql测试三:mlc+写优化flash
只有读的情况:
| 读压力 |
真实读压力 |
写压力 |
真实写压力 |
| 40线程*1000 |
8300+ |
0 |
0 |
| 40线程*80 |
2900 |
单线程*200 |
160-190 |
| 40线程*125 |
4000+ |
单线程*200 |
160~190 |
可见,mlc+写优化后,比slc在性能上有较大提升。
可以支持4000次读+160以上的写请求。
Mysql(InnoDB)刷盘策略
上面做了Mysql InnDB的一些性能测试,这里讲一下InnoDB的刷盘策略。InnoDB存储引擎会有一个缓冲池(缓冲池的大小可根据配置来修改innodb_buffer_pool_size),InnoDB在读数据库文件的数据时,会先将数据库文件按页读取这个buffer,然后按LRU的算法来保留缓冲池中的数据。当需要修改数据时,会先修改buffer里面的数据,此时buffer里的数据可能为脏数据,然后InnoDB会按一定的频率将缓冲池里的脏页刷新到文件。
对于刷脏页的时机和数量,Innodb会根据当然系统的IO压力等因素来决定是否刷盘。它会分每秒钟触发一次的刷盘和每10秒钟触发一次的刷盘。在每秒钟触发一次刷盘的条件是:当前缓冲池中脏页的比例超过了配置文件中innodb_max_dirty_pages_pct这个参数。而在每10秒钟触发一次的刷盘中,InnoDB至少会刷10个脏页(如果有的话)到磁盘,同时InnoDB引擎会判断缓冲池中的脏页的比例,如果超一定比例的话,会刷100个脏页到磁盘。
c/s模式通信性能
在这一节,我们用百度的UB框写了两个网络性能测试程序。主要测试数据包大小对网络服务的影响,以及跨机房之间的网络延迟数据。
程序&硬件:
网卡带宽:1000Mb
通信协议:ubrpc
配置:长连接、EPOOL、server配40线程
同机房:
请求包大小:13000byte/pack
单线程压: 1600/s, 网卡流量: 20.6Mb
8个线种压:9000/s, 网卡流量: 122Mb (基本达网卡极限)
请求包大小:1700byte/pack
单线程压: 2900/s, 网卡流量: 4.7Mb
36个线种压:稳定28000/s, 网卡流量: 50.3Mb (此时对于千兆网卡来说,带宽还非常充裕,但CPU r值已经在10左右。再往上压服务器出现不稳定现象。
跨机房延迟: 817us
请求包大小:1700byte/pack
单线程压: 860/s, 网卡流量: 1.4Mb
同样的程序,单线程压跨机房的性能明显下降,不到同机房的1/3。每个请求延迟达817us
直接文件存储
文件IO方式
直接文件存储指将内存中的数据直接写到磁盘上,我们通常用munmap、fwrite、pwrite和write等方式进行数据写入。反之用mmap、fread、pread和read等方式从磁盘文件载入数据到内存中。
Mmap/munmap
1. mmap/munmap是一种内存映射技术,它用于把磁盘文件映射到内存中,对内存中数据的修改,会被映射回磁盘;Linux内核会维护一个数据结构,以建立虚拟地址空间的区域与相关数据之间的关联。文件区间与它所映射到的地址空间的关联是通过优先树完成的,如图(1.1)所示。Mmap技术无论从速度还是易用性上都有着非常不错的表现。
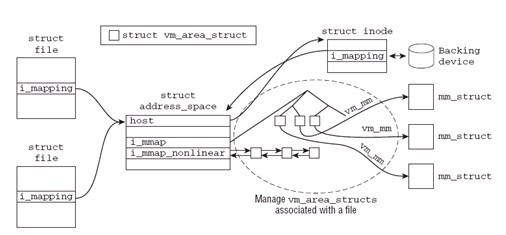
图1.1 struct file是指用open打开的一个文件句柄,其中f_mapping是包含一个指向inode和优先树的address_space结构体的指针,用做内存映射。
pwrite/write
其次,先说一下pwrite和write,它们都属于文件IO,数据流是从“进程=>fd=>文件”,都是直接调用系统调用的函数。两者不同的是,pwrite相当于顺序调用 lseek 和 write , 然后调用pread时,无法中断其定位和读操作,也就是说lseek和write相当于是原子操作;另外一点是pwrite不会更新文件的指针。
在多线程io操作中,对io的操作尽量使用pread和pwrite,否则,如果使用seek+write/read的方式的话,就需要在操作时加锁。这种加锁会直接造成多线程对同一个文件的操作在应用层就串行了。从而,多线程带来的好处就被消除了。
使用pread方式,多线程也比单线程要快很多,可见pread系统调用并没有因为同一个文件描述符而相互阻塞。pread和pwrite系统调用在底层实现中是如何做到相同的文件描述符而彼此之间不影响的?多线程比单线程的IOPS增高的主要因素在于调度算法。多线程做pread时相互未严重竞争是次要因素。
内核在执行pread的系统调用时并没有使用inode的信号量,避免了一个线程读文件时阻塞了其他线程;但是pwrite的系统调用会使用inode的信号量,多个线程会在inode信号量处产生竞争。pwrite仅将数据写入cache就返回,时间非常短,所以竞争不会很强烈。
在使用pread/pwrite的前提下,如果各个读写线程使用各自的一套文件描述符,是否还能进一步提升io性能?
每个文件描述符对应内核中一个叫file的对象,而每个文件对应一个叫inode的对象。假设某个进程两次打开同一个文件,得到了两个文件描述符,那么在内核中对应的是两个file对象,但只有一个inode对象。文件的读写操作最终由inode对象完成。所以,如果读写线程打开同一个文件的话,即使采用各自独占的文件描述符,但最终都会作用到同一个inode对象上。因此不会提升IO性能。
pwrite/fwrite
最后,说一下pwrite/fwrite。虽然他们的功能都是将内存中的数据存入文件。但原理和过程都有所不同。刚刚说过pwrite是属于文件IO,数据流是从“进程=>fd=>文件”,而fwrite是流/标准IO,其数据流是从“进程=>fp(FILE对象)=>流/缓冲=>文件”;原本直接对文件的操作,在fwrite库函数中变为对流对象的操作,而“流=>文件”这一层的操作将由库函数为我们完成。流的逻辑表示就是FILE对象,而流的实体就是流使用的缓冲区,这些缓冲区相对于应用进程来说就是文件的代表。
完全随机写还是跳跃,5倍的性能差距
全随机写无疑是最慢的写入方式,在logic dump测试中很惊讶的发现,将200M的内存数据随机的写入到100G的磁盘数据里面,竟然要2个小时之多。原因就是虽然只有200M的数据,但实际上却是200万次随机写,根据测试,在2850机器上,这样完全的随机写,r/s 大约在150~350之间,在180机器上,r/s难以达到250,这样计算,难怪需要2~3个小时之久。
如何改进这种单线程随机写慢的问题呢。一种方法就是尽量将完全随机写变成有序的跳跃随机写。实现方式,可以是简单的在内存中缓存一段时间,然后排序,使得在写盘的时候,不是完全随机的,而是使得磁盘磁头的移动只向一个方向。根据测试,再一次让我震惊,简单的先在内存中排序,竟然直接使得写盘时间缩短到1645秒,磁盘的r/s也因此提升到1000以上。写盘的速度,一下子提高了5倍。
一个需要注意的地方,这种跳跃写对性能的提升,来至与磁头的单方向移动,它非常容易受其他因素的影响。测试中,上面提到的测试是只写block文件,但如果在每个tid的处理中再增加一个写index的小文件。虽然如果只写index小文件,所用时间几乎可以忽略,但如果夹杂在写block文件中间的话,对整体的写性能可能影响巨大,因为他可能使得磁盘的磁头需要这两个地方来回跑。根据测试,如果只写index文件,只需要300s就可以写完所有200万个tid,单如果将写索引和写block放在一起,总时间就远大于分别写这两部分的时间的和。针对这种情况,一种解决方案就是就不要将小数据量的数据实时的刷盘,使用应用层的cache来缓存小数据量的index,这样就可以消除对写block文件的影响。
从原理上解释上面的表象,一般来说,硬盘读取数据的过程是这样的,首先是将磁头移动到磁盘上数据所在的区域,然后才能进行读取工作。磁头移动的过程又可以分解为两个步骤,其一是移动磁头到指定的磁道,也就是寻道,这是一个在磁盘盘片径向上移动的步骤,花费的时间被称为“寻道时间”;其二就是旋转盘片到相应扇区,花费的时间被称为“潜伏时间”(也被称为延迟)。那么也就是说在硬盘上读取数据之前,做准备工作上需要花的时间主要就是“寻道时间”和“潜伏时间”的总和。真正的数据读取时间,是由读取数据大小和磁盘密度、磁盘转速决定的固定值,在应用层没有办法改变,但应用层缺可以通过改变对磁盘的访问模式来减少“寻道时间”和“潜伏时间”,
我们上面提到的在应用层使用cache然后排序的方式,无疑就是缩短了磁盘的寻址时间。由于磁头是物理设备,也很容易理解,为什么中间插入对其他小文件的读写会导致速度变慢很多。
建议:尽量避免完全的随机写,在 不能使用多线处理的时候,尽量使用应用层cache,确保写盘时尽量有顺序性。对于小数据量的其他文件,可以一直保存在应用层cache里面,避免对其他大数据量的数据写入产生影响。
多线程随机读、处理速度、响应时间
多线程随机读的处理速度可以达到单线程随机读的10倍以上,但同上也带来了响应时间的增大。测试结论如下:(每个线程尽量读)
| 读线程数 |
读出100次耗时(um) |
读平均相应时间(um) |
| 1 |
1329574 |
13291 |
| 5 |
251765 |
12976 |
| 10 |
149206 |
15987 |
| 20 |
126755 |
25450 |
| 50 |
96595 |
48351 |
结论标明增加线程数,可以有效的提升程序整体的io处理速度。但同时,也使得每个io请求的响应时间上升很多。
从底层的实现上解释这个现象:应用层的io请求在内核态会加入到io请求队列里面。内核在处理io请求的时候,并不是简单的先到先处理,而是根据磁盘的特性,使用某种电梯算法,在处理完一个io请求后,会优先处理最临近的io请求。这样可以有效的减少磁盘的寻道时间,从而提升了系统整体的io处理速度。但对于每一个io请求来看,由于可能需要在队列里面等待,所以响应时间会有所提升。
响应时间上升,应该主要是由于我们测试的时候采用每个线程都尽量读的方式。在实际的应用中,我们的程序都没有达到这种压力。所以,在io成为瓶颈的程序里面,应该尽量使用多线程并行处理不同的请求。对于线程数的选择,还需要通过性能测试来衡量。
系统缓存
系统缓存相关的几个内核参数
- /proc/sys/vm/dirty_background_ratio
该文件表示脏数据到达系统整体内存的百分比,此时触发pdflush进程把脏数据写回磁盘。
缺省设置:10
- /proc/sys/vm/dirty_expire_centisecs
该文件表示如果脏数据在内存中驻留时间超过该值,pdflush进程在下一次将把这些数据写回磁盘。
缺省设置:3000(1/100秒)
- /proc/sys/vm/dirty_ratio
该文件表示如果进程产生的脏数据到达系统整体内存的百分比,此时进程自行把脏数据写回磁盘。
缺省设置:40
- /proc/sys/vm/dirty_writeback_centisecs
该文件表示pdflush进程周期性间隔多久把脏数据写回磁盘。
缺省设置:500(1/100秒)
dirty页的write back
系统通常会在下面三种情况下回写dirty页
- 定时方式: 定时回写是基于这样的原则:/proc/sys/vm/dirty_writeback_centisecs的值表示多长时间会启动回写线程,由这个定时器启动的回写线程只回写在内存中为dirty时间超过(/proc/sys/vm/didirty_expire_centisecs / 100)秒的页(这个值默认是3000,也就是30秒),一般情况下dirty_writeback_centisecs的值是500,也就是5秒,所以默认情况下系统会5秒钟启动一次回写线程,把dirty时间超过30秒的页回写,要注意的是,这种方式启动的回写线程只回写超时的dirty页,不会回写没超时的dirty页,可以通过修改/proc中的这两个值,细节查看内核函数wb_kupdate。
- 内存不足的时候: 这时并不将所有的dirty页写到磁盘,而是每次写大概1024个页面,直到空闲页面满足需求为止
- 写操作时发现脏页超过一定比例: 当脏页占系统内存的比例超过/proc/sys/vm/dirty_background_ratio 的时候,write系统调用会唤醒pdflush回写dirty page,直到脏页比例低于/proc/sys/vm/dirty_background_ratio,但write系统调用不会被阻塞,立即返回.当脏页占系统内存的比例超/proc/sys/vm/dirty_ratio的时候, write系统调用会被被阻塞,主动回写dirty page,直到脏页比例低于/proc/sys/vm/dirty_ratio
总结
本文给大家提供了一份不同存储模式下的性能测试数据,方便大家在今后的程序开发过程中可以利用这份数据选择合适的数据存储模式。同时讲述了关于文件IO读写操作以及系统缓存层面的一些问题。
转自:http://stblog.baidu-tech.com/?p=851
分享到:




{kind=link}

相关推荐
系统最大性能容量的预估方法、装置、设备及存储介质与流程.mht
Spong)于1978年报导的三层结构膜的极好干涉特性,对光学存储来说,不论是可逆介质的磁光型性能方面,还是相变型性能方面,最近都有重大的改善。这些最近报导的进展,指出了这些材料的以前研究者发现的一些主要限制...
网络游戏-网络性能监测方法、装置、计算机设备和存储介质.zip
通过受信号调制的激光束与记录介质相互作用时产生的状态变化逐点记录信号,读出时再用激光束投射到记录介质表面,从反射光的强度变化中读出信息。 光信息存储技术及性能指标概述全文共3页,当前为第2页。 1、信息...
行业-电子政务-性能调整方法、装置、存储介质及电子设备.zip
行业-电子政务-应用性能监控方法、装置、可读存储介质及电子设备.zip
行业分类-物理装置-一种提升终端性能的管理方法、装置及计算机可读存储介质
Hadoop在2.6.0版本中引入了一个新特性异构存储.异构存储关键在于异构2个字....而对于热数据而言,可以采用SSD的方式进行存储,这样就能保证高效的读性能,在速率上甚至能做到十倍于或百倍于普通磁盘读写的速度
摘要 作为一种新型的存储介质,...由于FLASH在结构和操作方式上与硬盘、E2ROM等其他存储介质有较大区别,使用FLASH时必须根据其自身特性,对存储系统进行特殊设计,以保证系统的性能达到最优。 2 FLASH的特点
43用于改进用于计算地预测目标对象的未来状态的方法的性能的方法,驾驶员辅助系统,包括这种驾驶员辅助系统的车辆以及相应的程序存储介质和程序_new.pdf
DAS就是普通计算机系统最常用的存储方式,即将存储介质(硬盘)直接挂接在CPU的直接访问总线上,优点是访问效率高,缺点是占用系统总线资源、挂接数量有限,一般适用于低端PC系统。SAN是将存储和传统的计算机系统...
9.1.1 ASM磁盘支持的存储介质 9.1.2 ASM初始化参数 9.1.3管理ASM实例 9.1.4 ASM实例访问认证 9.2管理ASM磁盘组 9.2.1 ASM磁盘组使用的原则 9.2.2磁盘Discovery机制 9.2.3加载、卸载磁盘组 9.2.4磁盘组属性 ...
5.4 对存储系统的要求 46 第6章 数据一致性 48 6.1 数据一致性概述 48 6.2 Cache引起的数据一致性问题 48 6.3 时间不同步引起的数据一致性问题 49 6.4 文件共享中的数据一致性问题 50 第7章 数据复制与容灾 51 7.1 ...
第3~6章从物理数据库部署、数据库访问设置、硬件资源设定、存储空间和内存资源的使用、实例配置与缓存优化等多方面讲解了数据库系统在部署阶段的性能优化问题;第7章探讨了如何平衡数据库可靠性和性能之间的矛盾;第...
这个系统以一个\"无限\"存储容量的SAN文件系统的面目出现,对所有用户和应用系统屏蔽具体的存储设备和介质,从而实现智能存储管理的理念。SMS具有以下功能:跨平台的SAN文件系统、高性能HSM功能、智能的存储介质管理...
中国石油研究所实施的BWFS v3.0系统采用SATA磁盘作为存储介质,硬件采用全冗余设计,并通过RAID 5和相关软件技术保证数据和系统的可靠性,使原有的应用软件未作任何改动,均可正常运行,有效地降低存储系统的投资。...
结合具体测试,分析了闪存内部并行对于文件系统的影响,得到F2FS较适合对基于闪存的星载存储进行数据管理,并结合数据管理需求提出了适用于星载环境下的几点改进方案,为星载环境下闪存文件系统设计和实现提供了研究...
山东 济南 250014)摘要:钴基合金和铁基合金磁性纳米颗料薄膜和纳米超晶格结构,由于具有较高的矫元力和各向异性能,较小的粒子尺寸分布和能形成“单域”结构等特性,从而成为颇有潜力的高密存储介质。最近几年,...
1、同步,要求主机的性能和网络带宽很高,数据复制的方式是时时的。 2、异步,采用最广泛的一种方式,数据复制的方式,中间有停留。 三、数据异地备份 这种方式是比较经济的,对业务的时时性要求不是很高的应用。...